검색결과 리스트
분류 전체보기에 해당되는 글 56건
- 2007.05.15 [스크랩] volatile - c keyword
- 2007.04.12 gcc 옵션 1
- 2007.02.22 [스크랩] ARM 레지스터에 관하여 1
- 2007.02.08 I2C Bus
- 2007.02.05 SLC/MLC
- 2007.01.27 ATSAM2133
 카페 > 임베디드 시스템(Device.. / 별빛님 카페 > 임베디드 시스템(Device.. / 별빛님 http://cafe.naver.com/kucira/484 http://cafe.naver.com/kucira/484 | ||
| ||
| this 포인터 (0) | 2008.08.13 |
|---|---|
| [스크랩] ioctl() (0) | 2008.08.11 |
| [스크랩] Mutex를 이용한 쓰레드 동기화 - 조인시 위키 (0) | 2008.08.01 |
| [스크랩] 쓰레드는 무엇이며, 왜 이용하는가 - 조인시 위키 (0) | 2008.08.01 |
| gcc 옵션 (1) | 2007.04.12 |
| #include〈stdio.h〉 int main() { printf(“hello gccn”); return 0; } |
| #define max(x, y) ((x) 〉(y) ? (x) : (y) /* 마지막에 ")"가 없다!!! */ int myMax(int a, int b) { return max(a, b); } |
| int func3(void); /* func3 선언 */ extern int mydata; /* mydata 선언 */ int func2(void) /* func2 정의 */ { …. } int func1(void) /* func1 정의 */ { int i; ….. func2(); ….. func3(); …. i= mydata+3; ….. } -- end of test1.c -- start of test2.c int mydata = 3; /* mydata 정의 */ int func3(void) /* func3 정의 */ { ….. } |
| this 포인터 (0) | 2008.08.13 |
|---|---|
| [스크랩] ioctl() (0) | 2008.08.11 |
| [스크랩] Mutex를 이용한 쓰레드 동기화 - 조인시 위키 (0) | 2008.08.01 |
| [스크랩] 쓰레드는 무엇이며, 왜 이용하는가 - 조인시 위키 (0) | 2008.08.01 |
| [스크랩] volatile - c keyword (0) | 2007.05.15 |
전에 일하던 때에 프로그램을 디버깅하면서 레지스터에대해서 정확한 개념이 없이 구름을 잡듯지나가던 때가 있었는데.. 이제는 어느정도 감이 잡힘니다.^^;
먼저 arm에서 cpu레지스터는 R0~R14, PC, CPSR이렇게 나누어지는데 총 17가지로 명명되는 레지스터가 있는데, 그럼 ARM에서의 레지스터는 총17개가 되어야한다고 생각하기 쉬운데, 총 37개가 된다고 합니다.
그 이유는 arm에서 레지스터는 cpu의 상태와 연관이 있는데 cpu의 상태는 대략 7가지 모드를 가지의 모드를 가지기 때문입니다..
ARM에서 CPU의 모드는 user, system, fiq, irq, supervisor, abort, undef 이상의 7가지 모드가 있다. 인터럽트가 발생을 하면 이 7가지 모드중을 하나의 상태를 cpu는 가지게되고, 각 모드마다 공통적으로 사용하는 레지스터가 있고, 특별하게 다른 기억장치를 쓰는 레지스터도 있다. R0~R7번,PC,CPSR은 어떤 모드에서건 공통적으로 사용을하고 나머지 레스트터는 상태에 따라 다른 레지스터를 사용한다.
일단 특정한 용도로 쓰이는 레지스터를 생각해보도록 하자.
R13은 SP라는 예약어로 어셈블러나, 소스레벨에서 끌어서 쓸 수가 있으며 각 모드마다 물리적으로 다른 레지스터가 사용된다. 단 user와 system모드에서는 같은 물리적 레지스터를 사용한다. 용도는 현재 모드의 스텍포인터를 저장하고 있다.
R14번은 LR이라는 약어로 쓰이며 어셈과 소스에서 사용이가능하고 서브루틴이 되돌아오기 위한 링크레지스터로 사용된다. LR또한 물리적으로 6개가 존재한다.
그리고 R15번은 PC라는 약어로 사용되며 program counter라고 하며, 현재 실행되는 인스트럭션의 주소관련 정보를 나타낸다.[1:0]비트는 0으로 세팅되며 [31:2]비트는 주소정보를 싫고있다.
또한 CPSR이라는 레지스터가 있는데 이는 current program status register의 약어이며, 현재 프로그램의 상태를 나타내며, [4:0]비트는 cpu의 7가지 모드정보를 가지고 있으며 [5]비트는 thum코드인지 arm코드인지를 나타낸고 [6]비트는 1로 세팅이되면 FIQ인터럽트를 튀지않게 할 수 있으며, [7]비트는 1로 세팅이 되면 IRQ인터럽트를 튀지 않게 할 수가 있다.
그리고 [31:28]까지의 4비트는 N,Z,C,V를 의미하며 negative, zero, carry, overflow비트들을 나타낸다.
그리고 user모드와 system모드를 제외한 5개의 모드에서 SPSR이라는 물리적으로 틀린 레지스터를 각 모드별로 가지고 있다. 이곳은 Exception이 일어났을때 CPSR을 저장해 놓기 위한 곳으로 사용된다.
이상이 arm에서의 레지스터에대한 간략한 설명이다.
더 자세한 내용은 armref문서를 같이 올려 놓았습니다.
 <그림 1>에서 보듯이 I2C 버스는 SDA(Serial DAta Line) 신호선과 SCL(Serial Clock Line) 신호선으로 통신의 주체가 되는 마스터인 MCU와 통신 대상이 되는 주변 장치인 슬레이브(slave) 간에 데이터를 전달하고 받는다.
<그림 1>에서 보듯이 I2C 버스는 SDA(Serial DAta Line) 신호선과 SCL(Serial Clock Line) 신호선으로 통신의 주체가 되는 마스터인 MCU와 통신 대상이 되는 주변 장치인 슬레이브(slave) 간에 데이터를 전달하고 받는다.◆ 마스터가 슬레이브에 전송을 시작한다는 표현 - Start
◆ 전송 목적지의 주소 표현 - Address
◆ 전송 목적 표현(읽기용인가 또는 쓰기용인가) - R/W
◆ 전송 데이터 표현 - Data
◆ 슬레이브가 정상적으로 데이터를 수신했다는 응답 표현 - Ack
◆ 전송 종료 표현 - Stop
 START 표현
START 표현 DATA 1비트 신호 표현
DATA 1비트 신호 표현 EEPROM
EEPROM i2c-dev 디바이스 파일은 주번호가 89이고 부번호가 0부터 시작하는 문자형 디바이스 파일이다. 부번호는 시스템에 존재하는 i2c 버스를 구별하는데 i2c 버스는 시스템에 하나 이상 존재할 수 있기 때문에 각 버스마다 0, 1과 같은 식으로 순서에 입각하여 부여한다. 보통 하나의 i2c 버스가 존재하는 경우가 대부분이기 때문에 /dev/i2c-0 라는 디바이스 파일만 있으면 된다.
i2c-dev 디바이스 파일은 주번호가 89이고 부번호가 0부터 시작하는 문자형 디바이스 파일이다. 부번호는 시스템에 존재하는 i2c 버스를 구별하는데 i2c 버스는 시스템에 하나 이상 존재할 수 있기 때문에 각 버스마다 0, 1과 같은 식으로 순서에 입각하여 부여한다. 보통 하나의 i2c 버스가 존재하는 경우가 대부분이기 때문에 /dev/i2c-0 라는 디바이스 파일만 있으면 된다.# mkdev c /dev/i2c-0 c 89 0
# mkdev c /dev/i2c-1 c 89 1
…
#define I2C_DEV_FILENAME “/dev/i2c-0”if( access( I2C_DEV_FILENAME , F_OK ) != 0 )
mknod( I2C_DEV_FILENAME, S_IRWXU|S_IRWXG|S_IFCHR,(89<<8|(0)));
int fd;fd = open( I2C_DEV_FILENAME, O_RDWR );
if( fd >= 0 )
{
:
:
close( fd );
}
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#include <sys/poll.h>
#include <termios.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <sys/stat.h>#include <linux/i2c.h>
#include <linux/i2c-dev.h>
 i2c-dev 디바이스 드라이버를 이용하여 EEPROM에 데이터 쓰기
i2c-dev 디바이스 드라이버를 이용하여 EEPROM에 데이터 쓰기 unsigned char eeprom_data[32]; // EEPROM 읽기 쓰기 데이터 버퍼ioctl( fd, I2C_SLAVE, 0x50 ); // 슬레이브 주소
 i2c-dev는 read 함수와 write 함수를 기본적으로 함수 호출시 START와 STOP을 발생시킨다. 그래서 START … START … STOP 형식을 사용하고자 한다면 read, write 함수를 사용할 수 없다. 이 때 사용하는 것이 ioctl 함수에 I2C_RDWR 명령을 사용하는 방법이다. 이런 형식으로 사용할 경우에 형식은 다음과 같다.
i2c-dev는 read 함수와 write 함수를 기본적으로 함수 호출시 START와 STOP을 발생시킨다. 그래서 START … START … STOP 형식을 사용하고자 한다면 read, write 함수를 사용할 수 없다. 이 때 사용하는 것이 ioctl 함수에 I2C_RDWR 명령을 사용하는 방법이다. 이런 형식으로 사용할 경우에 형식은 다음과 같다.ioctl( fd, I2C_RDWR, (struct i2c_rdwr_ioctl_data *) msgs );
struct i2c_rdwr_ioctl_data
struct i2c_rdwr_ioctl_data {
struct i2c_msg __user *msgs; /* pointers to i2c_msgs */
__u32 nmsgs; /* number of i2c_msgs */
};
struct i2c_msg
 이 구조체가 실제로 전달해야 하는 데이터의 각 블럭을 표현한다.
이 구조체가 실제로 전달해야 하는 데이터의 각 블럭을 표현한다.struct i2c_msg {
__u16 addr; /* slave address */
__u16 flags;
__u16 len; /* msg length */
__u8 *buf; /* pointer to msg data */
};
◆ I2C_M_TEN : 주소가 10비트이다.
◆ I2C_M_RD : 이 값이 지정되면 읽기 명령을 I2C 버스상에서 수행한다.
◆ I2C_M_NOSTART : START가 발생하면 안되는 패킷임을 표시한다. 가장 첫 번째 msg 블럭에는 사용할 수 없다.
◆ I2C_M_REV_DIR_ADDR : R/W가 반전된 처리를 해야 한다.
◆ I2C_M_IGNORE_NAK : NAK 응답 즉 ACK가 없더라도 에러 처리하지 않는다.
◆ I2C_M_NO_RD_ACK : 읽기에 따른 ACK가 없더라도 에러 처리하지 않는다.
struct i2c_msg i2c_msgs[2];
struct i2c_rdwr_ioctl_data i2c_rwctl;unsigned char eeprom_data_addres[2]; // EEPROM 데이터 주소 설정용 버퍼
unsigned char eeprom_data[32]; // EEPROM 읽기 쓰기 데이터 버퍼
 I2C 버스와 커널
I2C 버스와 커널 



linux/drivers/i2c/busses/
linux/drivers/i2c/algos/
static int iic_xxx_xfer(struct i2c_adapter *i2c_adap, struct i2c_msg msgs[], int num)
{
// I2C 버스 제어를 위한 구현 루틴
return ret;
}
static struct i2c_algorithm iic_xxx_algo =
{
.name = “Sample IIC algorithm”,
.id = I2C_ALGO_SAMPLE,
.master_xfer = iic_xxx_xfer,
};
static struct i2c_adapter iic_xxx_adapter =
{
.owner = THIS_MODULE,
.name = “Sample IIC adapter”,
.algo = &iic_xxx_algo,
};
static int __init iic_xxx_init(void)
{
iic_xxx_hw_init(); // I2C 버스를 제어하기 위한 하드웨어 초기화 루틴 메모리 할당, 인터럽트 등록 처리
i2c_add_adapter( &iic_xxx_adapter ); // 어댑터 등록
return 0;
}
static void iic_xxx_exit(void)
{
i2c_del_adapter(&iic_xxx_adapter); // 어댑터 등록 해제
iic_xxx_hw_release (); // I2C 버스를 종료하기 위한 하드웨어 셧다운 루틴 메모리 해제, 인터럽트 제거 처리
}module_init(iic_xxx_init);
module_exit(iic_xxx_exit);MODULE_AUTHOR(“you young-change <frog@falinux.com>”);
MODULE_DESCRIPTION(“I2C-Bus adapter sample routines”);
MODULE_LICENSE(“GPL”);
int iic_xxx_xfer(struct i2c_adapter *i2c_adap, struct i2c_msg msgs[], int num)
◆ i2c-algo-bit.c : GPIO 를 이용하여 구현하는 경우에 사용한다.
◆ i2c-algo-pcf.c : 전용 컨트롤러를 사용하여 구현하는 경우 참조할 수 있는 소스
◆ i2c-algo-ite.c : 전용 컨트롤러를 사용하여 구현하는 경우 참조할 수 있는 소스
| 크롬 카나리아 빌드 + GPU (0) | 2011.01.25 |
|---|---|
| fatal error C1083: 포함 파일을 열 수 없습니다. 'atlapp.h': No such file or directory (0) | 2011.01.12 |
SLC : Single Level Cell
MLC : Multi Level Cell
기본적으로 메모리는 저장공간(여기서 제가 알기 쉽게 '컵'이라고 표현하겠습니다)에 전자가 있느냐 없느냐에 따라 아래와 같이 0 혹은 1로 표현됩니다. 아래 그림이 기본적인 SLC의 원리입니다.
(그런데 전자가 있다고 꼭 1 이 아닙니다. 메모리 설계에서 정하기 나름입니다. 즉 전자가 있을때 0으로도 할수 있습니다.)
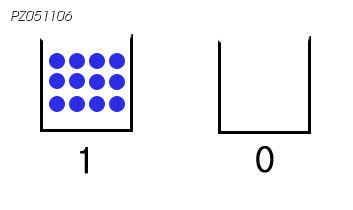
SLC
MLC는 아래와 같습니다. 즉 컵에 전자를 몇개를 저장하느냐에 따라서 여러가지 상태를 나타낼수 있습니다. 아래의 그림과 같이 전자가 없으면 00, 전자가 4개 있으면 01, 8개 10, 12개 11로 표현할수 있습니다.
즉 한개의 컵으로 총 4가지(00, 01, 10, 11)를 표현할 수 있습니다. 위의 SLC에 비해서 2배의 용량을 가지는 거죠. 아래 그림은 4 Level을 가지는 Cell을 표현했지만, 8Level Cell, 16 Level Cell도 이론적으로 가능하지만 아직까지 양산에 성공한 적은 없습니다.
MLC
*참고 : 전자들을 저장할수 있는 컵은 DRAM의 경우 Capacitor로 되어 있습니다. 많이들 아시겠지만 Capacitor는 전자를 저장할 경우 1초도 안되어 방전되고 맙니다. 그래서 DRAM은 Data를 보존하기 위해서 계속 전기가 공급되어야 하죠.
반면 Flash의 경우 전자를 저장할수 있는 컵이 옥사이드로 구성되어 있습니다. 이곳에 저장되면 10년이상 동안 보존되죠.
그렇다면 MP3 혹은 Memory Card에 사용되는 NAND Flash의 기본적인 구조를 보세요. 아래와 같습니다.
Cell 과 Logic으로 구성됩니다.
Cell에는 순수하게 Data가 저장되는 공간입니다. 최근 삼성에서 16Gbit의 NAND Flash를 개발했죠. 이건 Cell들이 총 16기가개(2^34 맞나요??)가 있다는 얘기 입니다.
Logic에는 Cell을 찾아가기 위한 회로, 각종 레지스터등으로 이루어져 있습니다.
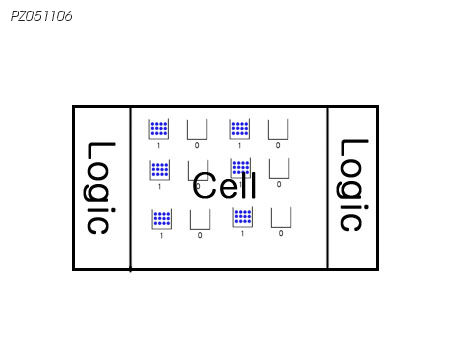
가령 MP3 파일을 NAND Flash에 저장한다고 가정합니다. 이 MP3 파일은 Binary로 바꿀경우 01001110 총 8bit으로 이루어 졌다고 가정합니다.
그렇다면 SLC에 이 MP3 파일을 저장하기 위해서는 8개의 컵(Cell)이 필요하지만
MLC에 저장하면 4개의 컵(Cell)으로 표현할수 있죠.
그렇다면 같은 컵의 개수를 가지고도 MLC를 만들면 2배의 용량을 가지는 Flash를 만들수 있습니다.
즉 아래의 같은 웨이퍼로 4Gbit SLC 칩을 100개를 만들수 있다면 같은 용량의 4Gbit MLC는 170개 이상을 만들수 있습니다. 여기서 딱 두배인 200개가 안나오는 이유는 위에서 설명했지만 Flash는 Cell 뿐만 아니라 각종 Logic으로 이루어졌기 때문에 그부분은 줄어들지 않습니다.
그렇다면 MLC는 왜 성능이 떨어지는가?
SLC의 경우 컵에 전자들을 한꺼번에 옮길수 있습니다. 즉 컵에 물을 한꺼번에 담기 때문에 빠른시간에 저장할수 있습니다.
그렇지만 MLC는 정확한 개수를 저장해야 하기 때문에 스포이드로 일정량을 옮기듯이 천천히 저장해야 합니다. 그래서 시간이 많이 걸리죠.
간단히 MLC와 SLC의 차이와 방식에 대해서 설명드렸습니다.
현재 MLC는 NAND Flash와 NOR Flash에서 사용되고 있습니다.
*참고2: NOR와 NAND
흔히 Flash는 NOR 타입과 NAND 타입으로 나뉩니다. Cell 방식은 비슷하지만 칩을 구성하는 방식에서 차이가 납니다. 특히 NOR Flash는 CPU의 구조와 비슷하여 CPU를 잘만드는 AMD와 INTEL에서 세계시장을 대부분을 차지하고 있습니다. NAND의 경우는 삼성과 도시바가 대부분을 차지하죠.
NOR는 Read가 빠르고 안정적이고, NAND는 Write가 빠르고 대용량하기 쉽습니다. 그래서 NOR의 경우 핸드폰등의 OS(Firmware등)을 저장하는곳에 많이 쓰이고, NAND의 경우 메모리카드, MP3등에 많이 사용됩니다.
예전에 누군가가 그러더군요. 반도체는 외국 장비를 수입해서 찍어내기만 하면 되는게 아니냐고.
아닙니다. 설계에서 양산까지 수년이 걸리고, 천문학적인 개발비가 들어갑니다.
| VS 2005 에서 msdia80.dll 문제 발생 (0) | 2011.03.21 |
|---|---|
| 아웃룩 실행시 시작할 폴더 변경 (2) | 2011.01.13 |
| 티스토리에서 source code에 syntax highlight 기능 사용하기 (0) | 2008.08.27 |
| BlogAPI 사용해보기 – Windows Live Writer (0) | 2008.08.01 |
| Microsoft Outlook 2007에서 한자 찾기 팁 (0) | 2008.07.29 |
| ATSAM2133B | |||||||||
| |||||||||
|
Datasheets:
| |||||||||
| ATSAM2133B (22 pages, updated 05/03) | |||||||||
|
Tools & Software:
| |||||||||
| |||||||||
|
| |||||||||


 invalid-file
invalid-file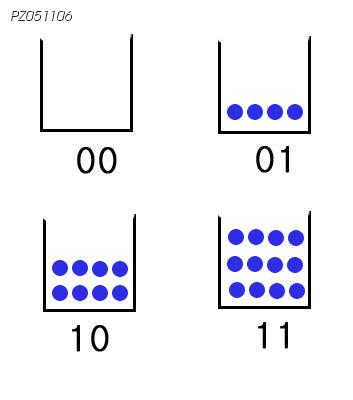

RECENT COMMENT