쓰레드는 무엇이며, 왜 이용하는가
쓰레드는 세미(semi)프로세스, 혹은 Light Weight 프로세스라고 불리우며, 여러개의 클라이언트를 처리하는 서버/클라이언트 모델의 서버프로그래밍 작업을 위해서 주로 사용된다. 비슷한 일을 하는 fork(2) 에 비해서 빠른 프로세스 생성 능력과, 적은 메모리를 사용하는게 Light Weight 프로세스라고 불리우는 이유이다.
보통의 유닉스 프로세스는 main()함수에 의해서 시작되고 실행되는 single 쓰레드 로 이루어지며, 하나의 연속된 명령어들만을 처리한다. 반면 멀티쓰레드 프로그램은 여러개의 연속된 명령어들을 동시에 처리할수 있다.
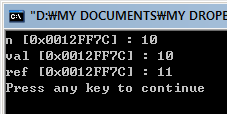
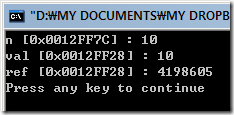
스레드는 자기자신의 스택메모리영역을 가지고, 코드의 조각을 실행한다. 실(real) 프로세스 와는 달리 쓰레드는 다른 형제 쓰레드들과 메모리를 공유하게 된다.(보통 프로세스는 자기자신만의 메모리영역을 가진다). 이렇듯 전역 메모리를 공유하게 되므로 fork 방식에 비해서 좀더 작은 메모리를 소비하게 된다.
fork 에 비해서 thread 가 가지는 장점은 위에서 언급했듯이 "빠른 프로세스 생성" 능력과, 메모리 공유에 위한"적은 메모리의 사용"과 메모리 공유에 따른 쓰레드간의 좀더 쉬운 정보공유이다. fork(2) 시스템에서 부모와 자식같이 통신을 위해서는 IPC를 사용해야 하며 이는 꽤 어려운 작업이 될수도 있는데, 메모리를 공유함으로 IPC의 사용을 줄이면서도 쓰레드간 정보교환을 쉽게 할수있다.
fork 에 비해서 쓰레드가 더 빠른 수행능력을 보이는 이유는 fork 가 기본적으로 모든 메모리와 모든 기술자(파일기술자등)을 copy-on-write 방식으로 자식에게 복사하는데 비해서 쓰레드는 많은 부분을 공유하기 때문이다. copy-on-write 자체가 효율적이긴 하지만, 메모리 자원을 공유하는 것보다는 느릴 수 밖에 없다.
반면 단점도 가지고 있는데, 모든 쓰레드가 같은 메모리 공간을 공유하게 되므로, 하나의 쓰레드가 잘못된 메모리연산을 하게 되면, 모든 프로세스가 그 영향을 받게 된다는 것이다. fork 등을 통한 프로세스 생성방식에 있어서는 OS 가 가각의 프로세스를 보호해줌으로 한 프로세스의 문제는 해당 프로세스의 문제로 끝나게 된다. 그러나 쓰레드는 이러한 프로세스 보호를 기대할수 없다. 하나의 쓰레드에 문제가 생기면 전체 쓰레드에 문제가 생길가능성이 크다. 이런 이유로 멀티 쓰레드 프로그램은 좀더 주의를 기울여서 작성해야 한다. 또단 하나의 흐름을 가지는 단일 프로세스 프로그램과 달리, 여러개의 흐름으로 분리가 되기 때문에, 디버깅을 하기가 까다롭다는 문제도 가진다.
아래는 쓰레드간에 서로 공유하는 자원들을 나열한 것이다.
다음은 각각의 쓰레드가 고유하게 가지는 자원들을 나열한 것이다.
- 에러번호(errno)
- 쓰레드 우선순위
- 스택
- 쓰레드 ID
- 레지스터 및 스택지시자
다음은 멀티쓰레드 프로세스가 어떻게 각종 자원을 공유하는지를 나타낸것이다.

파일은 기본적으로 공유하며, 메모리 영역중에 상당부분을 공유한다는걸 볼수 있을것이다.
POSIX thread
흔히 Pthread 라고 불리우며, POSIX 에서 표준으로 제안한 thread 함수모음으로 thread 를 지원하기위한 C 표준 라이브러리 셋을 제공한다. 이후 모든 예제는 Pthread 를 통해서 구현하고 설명하게 될것이다.
쓰레드의 생성과 종료
멀티 쓰레드 프로그램이 처음 시작되었을때 그것은 main()함수를 실행하는 단일 프로세스 상태로 작동하게 될것이다. 이것은 그 자체로 하나의 완전한 쓰레드이다. 이 상태에서 우리는 pthread_create(3) 함수를 부름으로써 새로운 쓰레드를 생성할수 있다.
쓰레드를 이용한 프로그램은 기본적으로 아래와 같은 순서로 작동하게 된다.
Master Thread
|
| pthread_create() 에 의해서 worker 생성
|
+---+----+---+ worker 시작
| | | |
| | | | 각각의 worker는 그들의 작업을 수행한다.
| | | |
+---+----+---+ worker 를 종료한다.
|
| pthread_join()에 의해서 worker 를 join 한다.
|
Master Thread
worker 은 쓰레드로 바꾸어 생각할수도 있다.
아래는 쓰레드 프로그램의 가장 간단한 예이다.
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
void* do_loop(void *data)
{
int i;
int me = *((int *)data);
for (i = 0; i < 10; i++)
{
printf("%d - Got %d\n", me, i);
sleep(1);
}
}
int main()
{
int thr_id;
pthread_t p_thread[3];
int status;
int a = 1;
int b = 2;
int c = 3;
thr_id = pthread_create(&p_thread[0], NULL, do_loop, (void *)&a);
thr_id = pthread_create(&p_thread[1], NULL, do_loop, (void *)&b);
thr_id = pthread_create(&p_thread[2], NULL, do_loop, (void *)&c);
pthread_join(p_thread[0], (void **) &status);
pthread_join(p_thread[1], (void **) &status);
pthread_join(p_thread[2], (void **) &status);
printf("programing is end\n");
return 0;
}
위의 프로그램을 컴파일 시키기 위해선 pthread 라이브러리를 링크시켜줘야 한다.
[yundream@localhost test]# gcc -o thread thread.c -lpthread
최초에
main() 쓰레드가 시작되고 나서 pthread_create 를 이용해서 3개의 쓰레드를 생성 시켯다. 각각의 쓰레드는 do_loop 코드를 실행한다. 쓰레드가 모든 작업을 마쳤다면, pthread_join 을 이용해서 다른 쓰레드가 종료될때까지 기다리고, 모든 쓰레드가 종료되었다면,
main()쓰레드가 종료되고 프로세스는 완전히 끝나게 된다.
쓰레드의 생성은 pthread_create()를 호출함으로써 이루어진다. 첫번째 아규먼트는 pthread_t 데이타 구조체에 대한 포인터를 돌려주는데, 쓰레드에 대한 지시값이 들어 있다. 각각의 쓰레드는 각각의 유일한 pthread_t 를 가지고 있어야만 한다. 위의 프로그램에서 우리는 각각의 쓰레드가 유일한 p_thread 를 가지도록 하기 위해서 생성할 쓰레드의 수만큼(3)을 배열로 만들었다. 2번째 아규먼트는 쓰레드가 만들어질때의 타입이다.
(스케쥴링 우선순위 같은). 보통은 NULL 값을 사용한다. 쓰레드 타입에 대한 내용은 pthread_attr_init(3) 을 참조하기 바란다. 3번째 아규먼트가 바로 쓰레드가 실행할 코드이다. 4번째 아규먼트는 쓰레드에 넘겨주고 싶은 값을 명시해주면 된다. 여기에서는 각 쓰레드에 번호를 부여하기위한 int 값을 넘겼다.
각 쓰레드는 1부터 10까지 증가 시킨다음에 쓰레드를 종료하도록 되어 있다.
그동안 메인 쓰레드는 pthread_join 을 호출하여서 각각의 쓰레드가 종료할때까지 기다린다. 3개의 쓰레드가 모두 종료가 된다면 메인 쓰레드는 "programing is end" 메시지를 출력하고 프로그램을 완전히 종료하게 될것이다.
pthread_join 은 fork 의 wait(2) 와 비슷하다고 볼수 있다. fork 에서도 자식프로세스가 모두죽고 나서 부모프로세스가 죽어야 하듯이(예외를 만들수도 있지만), 쓰레드도 모든 생성된 쓰레드가 종료된 다음에 메인 쓰레드가 종료되어야 한다.
pthread_join 을 사용하게 되면 메인 쓰레드는 pthread_join 에 명시된 쓰레드가 종료할때까지 잠자면서(sleep)기다리게 된다. 이는 모든 쓰레드가 종료하기 전에 부모쓰레드가 종료하는 사태를 막기 위해서 사용된다. 하나의 쓰레드가 모든일을 종료하고, pthread_join 을 깨우게 되면, 쓰레드가 가지고 있던 자원들을 모두 되돌려주게 된다 (free). 만약 실행되고 있는 쓰레드를 즉시 중지하길 원한다면 pthread_cancel() 과 pthread_testcancel()을 사용하면 된다.
공용으로 사용되는 자원의 동기화
위에서 우리는 쓰레드를 사용할경우 상당히 많은 자원을 서로 공유하게 됨으로 얻는 여러가지 이점에 대해서 알아봤었다. 그러나 하나의 자원을 여러개의 쓰레드가 동시에 공유하게 됨으로 자원획득에 관한 문제가 발생할수 있다. 실지로 쓰레드를 사용하게 될경우 가장 주의해야 할점 중 하나가 바로 자원의 동시 접근에 대한 제어이다.
기본적으로 하나의 쓰레드가 하나의 자원에 접근하고 있을때, 다른 쓰레드는 그 자원에 대한 이전 쓰레드의 작업이 모두 끝나기전엔 접근하면 안될것이다.
이런한 공유되는 자원에 대한 접근제어는 IPC 설비의 세마포어와 매우 비슷한 점이 있다. 쓰레드에서는 이러한 공유되는 자원의 접근 제얼르 위해서 Mutexe 라는 것을 제공한다. Mutexe 는 다루어야할 내용이 꽤 많음으로 다음번 강좌에서 다루도록 하겠다.
2008/08/01 - [C/C++] - [스크랩] Mutex를 이용한 쓰레드 동기화 - 조인시 위키




RECENT COMMENT